Everyone knows how to search the web. It’s part of our vernacular. But “googling it” was not always a given. In the early days of the web, discovering new sites looked a lot different.
The first web servers to come online came mostly from academic and scientific institutions, and in some rarer cases, dedicated hobbyists. The web community was a relatively close-knit one with an esoteric skill-set and knowledge base. So Tim Berners-Lee, creator of the web, took a very pragmatic approach to keeping track of new websites. He made a list for everyone to see. A list of every single website. Except he wrote his list in hypertext.
When new sites were created, the site owner could send a link over to Berners-Lee, who would, in turn, add it to info.cern.ch/Overview.html, a page on the first website ever created. This eventually came to be known as the WWW Virtual Library, an attempt by Berners-Lee to keep track of every website out there, organized by category. For a little while, it all stayed that simple. If you were looking for new websites, you could just check the list.
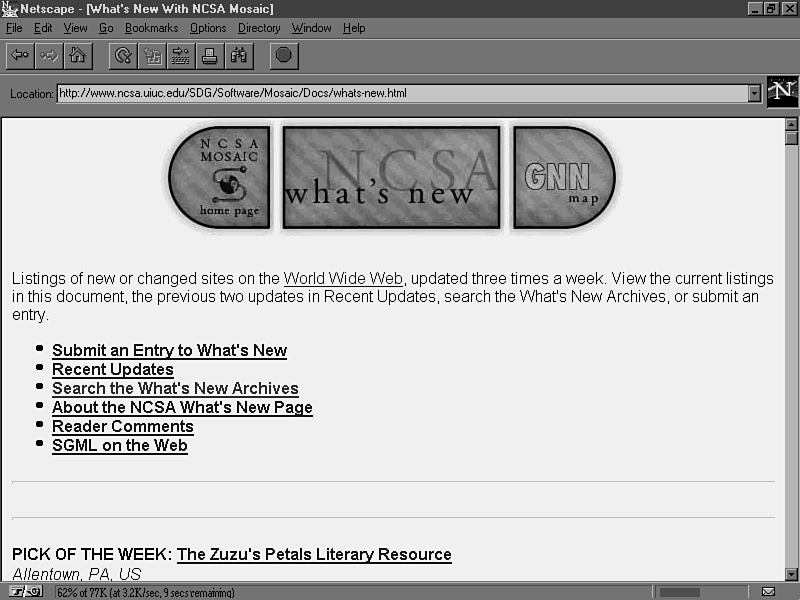
In June of 1993, the web was showing signs of truly taking off. To keep track, NCSA started a list of their own which they called “What’s New.” Each day, the team would add a few new links for visitors to check out. At the time, NCSA was best known for Mosaic, later Netscape Navigator, later Mozilla Firefox. Their browser was extremely popular in the early days of the web. So the “What’s New” page had a lot eyeballs and site owners were motivated to send them links to put up.
O’Reilly Media was the next to throw their hat into the ring. In August of 1993, they created the Global Network Navigator website, their own take on web discovery. GNN is credited as the first web publication, and built on the success of Ed Krol’s Whole Internet User’s Guide and Catalog. The User’s Guide offered readers a tour of the Internet and the World Wide Web. The GNN site included this tour in a more interactive form, alongside news and a global directory of sites for various products and services. GNN would later break new ground experimenting with advertising and publishing techniques. But when it first launched in the summer of ’93, its goal was to help visitors discover the magic of the web.
Modern search technology is based on the premise of crawling. Search engines send out bots to crawl through websites, scrape their content, and then index it. This indexed information is then paired to a text based search. But in the early 90’s, nothing like this existed on the web. The concept, however, was not unheard of. Archie was a system that used crawling to help users find FTP files, and is commonly known as the Internet’s first search engine. But it took Matthew Gray to bring crawling to the web.
While NCSA was getting their “What’s New” page up and running, Gray was working at the Massachusetts Institute of Technology on a new tool he dubbed the World Wide Web Wanderer (catchy, I know). The Wanderer was able to traverse a large part of the web automatically by scraping its content one by one. This data was then compiled into a database known as the Wandex.
The Wanderer had a few initial kinks to work out. In its earliest version, the crawler would access the same websites hundreds of times a day, causing most still nascent (and fragile) sites to crash. Gray fixed this issue pretty quick though, and the Wandex grew. The Wandex, however, was not used as a search engine, and certainly not in the way we think of today. Instead, the Wandex gave an overview of the state of the web. It was built to track the growth of the web over time. So visiting the Wanderer’s website would give you stats on how many servers and websites were online. But it didn’t provide much in the way of search.
Crawling was used in less traditional ways as well. In September of 1993, Oscar Nierstrasz created a new site called W3Catalog. Its premise was simple. Take high quality lists like the WWW Virtual Library and NCSA What’s New entries and put them all in one place. The curated listicle is almost as old as the web itself.
Nierstrasz used a custom built scraper built in Perl to index these lists from time to time and download them to a centralized webpage. There, visitors could peruse the best of all worlds, and get a more complete picture about the latest and greatest websites. Combining curation and automation, W3Catalog took advantage of the standards and openness of the web to create a one of a kind discovery tool.
Not long after the release of W3Catalog, new search engines began sprouting up. These relied more heavily on crawling and indexing, and less on manual curation. Soon this became the dominant method of search, and the curated list retreated to individual blogs in the form of blogrolls, where site owners would hyperlink their favorite sites. Publications like GNN and What’s New continued of course, but the web mostly outpaced these efforts. Search continues to evolve, but its still fun to remember a time when getting noticed was as simple as emailing the creator of the web and saying “Hey, I’ve just set up a server, and it’s dead cool. Here’s the address.”
Don’t miss http://vlib.org/admin/history where I saw this and of course, https://thehistoryoftheweb.com/